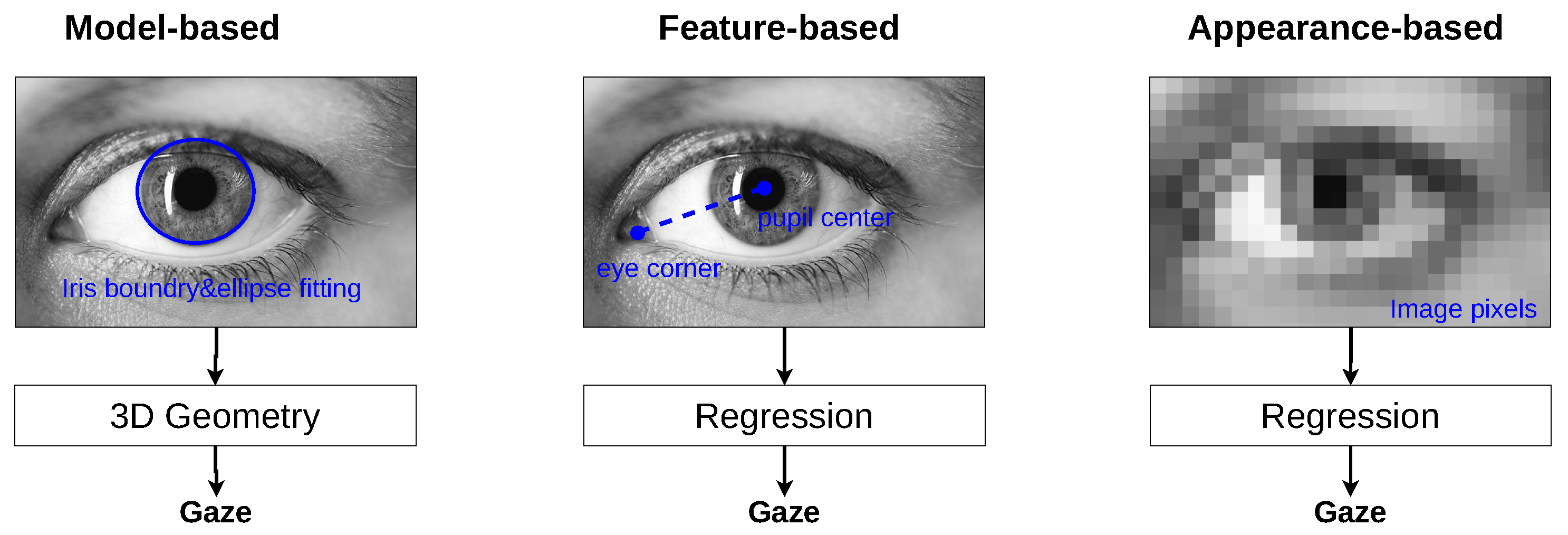
Gaze estimation, a critical facet of understanding user intent and enhancing human–computer interaction, has seen substantial advancements with the integration of deep learning technologies. Despite the progress, the application of deep learning in gaze estimation presents unique challenges, notably in the adaptation and optimization of these models for precise gaze tracking. This paper conducts a thorough review of recent developments in deep learning-based gaze estimation, with a particular focus on the evolution from traditional methods to sophisticated appearance-based techniques. We examine the key components of successful gaze estimation systems, including input feature processing, neural network architectures, and the importance of data preprocessing in achieving high accuracy. Our analysis extends to a comprehensive comparison of existing methods, shedding light on their effectiveness and limitations within various implementation contexts. Through this systematic review, we aim to consolidate existing knowledge in the field, identify gaps in current research, and suggest directions for future investigation. By providing a clear overview of the state-of-the-art in gaze estimation and discussing ongoing challenges and potential solutions, our work seeks to inspire further innovation and progress in developing more accurate and efficient gaze estimation systems.
Fulltext Access
https://www.mdpi.com/2218-6581/15/4/69
Citing
@Article{Abdelrahman2026,
author={Abdelrahman, Ahmed and Al-Tawil, Basheer and Al-Hamadi, Ayoub},
journal={Robotics},
title={Deep Learning-Based Gaze Estimation: A Review},
year={2026},
doi={10.3390/robotics15040069}}