Cross-Modal Fusion Mamba for Multimodal Depression Detection
Cross-Modal Fusion Mamba for Multimodal Depression Detection
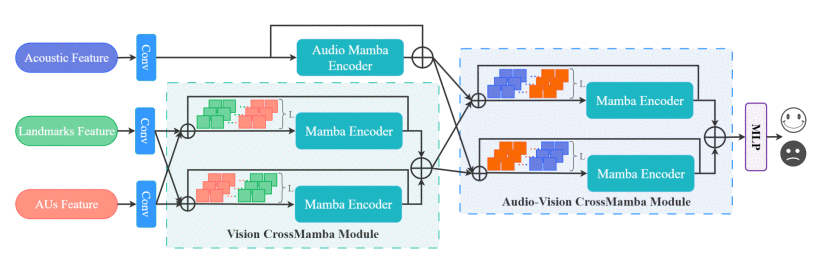
Depression detection using multimodal signals has garnered growing attention due to its potential for early warning. However, existing approaches often rely on limited visual features or computationally intensive fusion mechanisms. In this study, we present a novel framework based on the Mamba structure to address these challenges. Our method fuses audio features with enriched visual representations by combining facial landmarks and action units (AUs), enhancing the expressiveness of visual cues. To capture intramodal information, we propose the Audio Mamba Encoder (AME) for audio modality, and the Vision CrossMamba (VCM) module for visual feature fusion. Furthermore, the Audio-Vision CrossMamba (AVCM) module is designed for intermodal interactions. Experimental results demonstrate superior performance over several baselines, highlighting the effectiveness of the proposed framework in detecting depression from multimodal data.
Fulltext Access
https://ieeexplore.ieee.org/document/11259458
Citing
@INPROCEEDINGS{Zhou2025,
author={Zhou, Bowen and Fiedler, Marc-André and Al-Hamadi, Ayoub},
booktitle={2025 14th International Symposium on Image and Signal Processing and Analysis (ISPA)},
title={Cross-Modal Fusion Mamba for Multimodal Depression Detection},
year={2025},
doi={10.1109/ISPA66905.2025.11259458}}